Having your data infrastructure in the cloud has become a real option for a lot of companies, especially since the big cloud providers have a lot of managed services available for a modern data architecture aside from just a database management system.
In this article I will look into what the three big cloud providers offer in tools to support a modern data architecture.
Modern Data Infrastructure Setup
A generic data infrastructure looks like the picture shown below. It contains one data entry point, where all data is collected as the general API for all producers of data. This data is pushed in single events, whenever possible and defined using a schema. All of the schemas are defined and stored in a schema registry.
Following this entry point there is the possibility to do some ETL, like collecting several messages for one event into bigger chunks. This is useful for writing data out onto a storage or inserting into an analytical database. As these do not handle single row operations as well as bulk ones. Storing raw event data on a cloud storage is also possible and then access these files using SQL from the DWH system. This potentially saves more expensive storage in the DWH system.
After the initial ETL transformations done on the events it seems sensible to do all the other transformations from the source using the compute power of the database system. As this can be done by using SQL, this offers the possibility to have people like analysts with SQL knowledge participate in the process. No other programming skills are needed from this point on.

Next we will look into the tools offered by the three largest cloud vendors that support this setup.
Google Cloud Platform
The Google Cloud Platform offers tools to implement this architecture, as seen in the image below.

- Schema Registry: Google offers no dedicated schema registry, but it is possible to use the Confluent Schema Registry, if needed. If you want to use AVRO schemas it is possible to use this schema repo, but it is not maintained anymore.
- PubSub is a messaging system. It only delivers once and data replay is not possible. The messages are also not ordered.
- Cloud Dataflow is a serverless data processing platform, which can be programmed using Apache Beam. The upside of using Apache Beam is that it supports several processing platforms, like Spark, Flink. So you are flexible to move away from Dataflow, if you chose to.
- Cloud Storage is a managed object storage form Google.
- Bigquery is Google’s solution for a Datawarehouse. It is kind of a specialized SQL on Hadoop solution and serverless. Compute and storage are seperated, so the engine scales for each query as needed.
Amazon Web Services
Amazon Web Services also offers tools to implement the data architecture.

- AWS Glue provides a schema registry that can be used for Kinesis streams and transformations.
- Kinesis Data Stream provides a platform for streaming events. Data replay is possible here and messages are stored in an ordered fashion.
- Kinesis Firehose takes the data streams and offers some in-built transformations like storing data aggregated in an Apache Parquet or Apache ORC format. Both formats are column oriented and fast to query from their Datawarehouse solution Redshift. Custom transformations are also supported using AWS Lambda. Lambda provides serverless computing for transformation code.
- S3 offers cheap object storage for object from Amazon
- Redshift is Amazon’s datawarehouse solution. It is a multi-parallel-processing engine (MPP) based on a PostgreSQL database. Here compute and storage are not seperated, so you need to size your cluster appropriately. Also there is some administrative effort necessary for data optimizing. This includes vacuuming, index creation, and table analysis. Sizing is also a manual task.
Microsoft Azure
Microsoft Azure offers other tools that support this data infrastructure in the cloud.
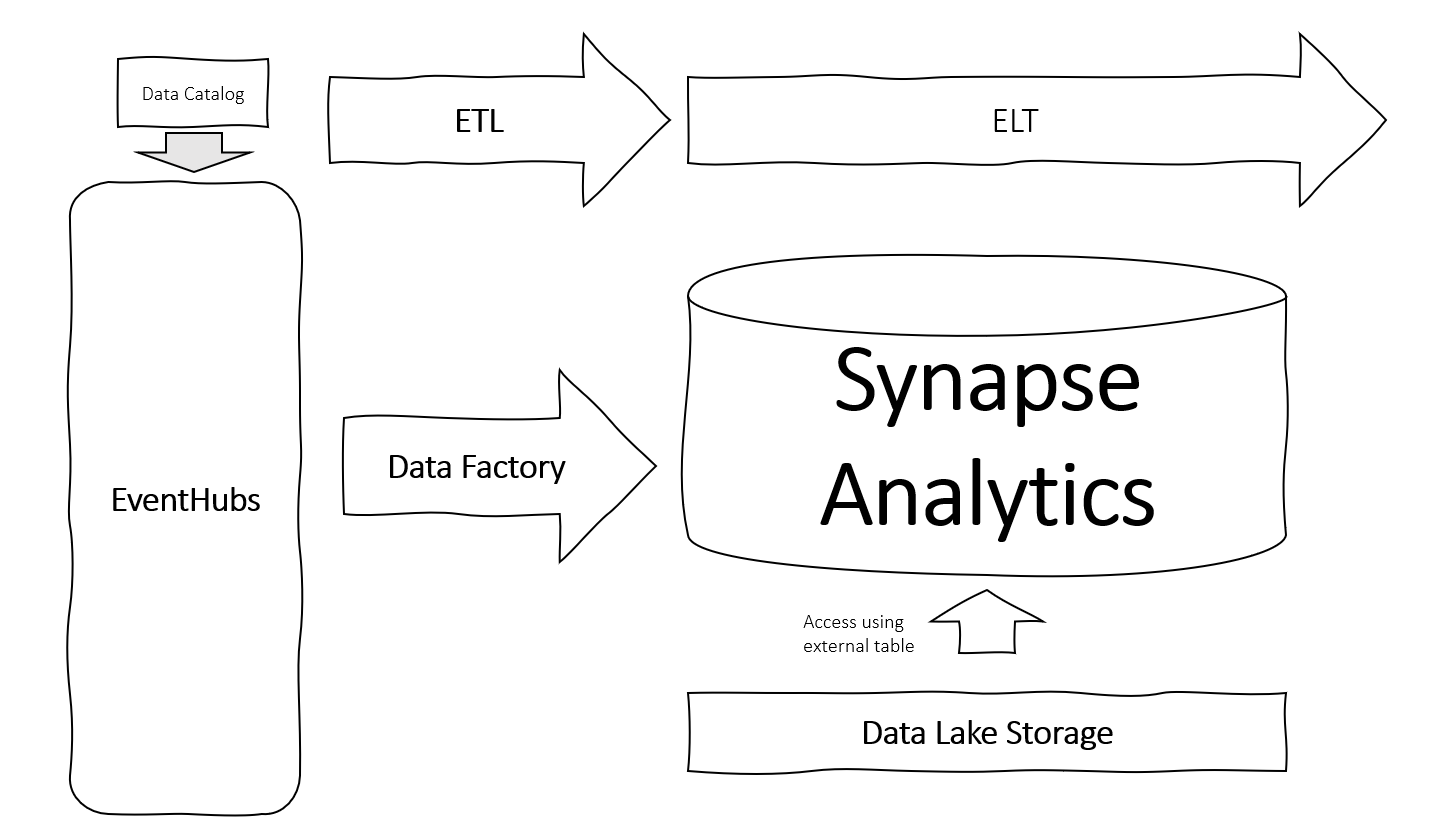
- Data Catalog discovers data schemas and you can define them here as well.
- EventHubs is a serverless streaming solution for events. Events can be ordered by using the partitioning function that is provided.
- Data Factory enables you to collect and transform all data coming into the data platform.
- Data Lake Storage object storage for data analytics that decouples compute from storage.
- Synapse Analytics is a framework for storing and analysing all data, like Spark or an MPP engine for SQL workloads. It seemlessly integrates with long existing MS products like SSIS.
Conclusion
Data Infrastructure in the Cloud is possible with all three major cloud providers. Each of them offers tools to set up this solution. Which one fits your needs best depends propably most on the preference and knowledge of your data engineers, scientists and analysts or even your other infrastructure setup.